Example: Linear Graph Dynamics - Part 2/2¶
Author: Dr. Daning Huang
Date: 10/28/2025
Updated: 05/07/2026
Introduction¶
In part 1 of the example, we showed using GNN as the autoencoder. In this part, we will turn to the case of GNN as dynamics.
To make the discussion tangible, let’s consider one simple dynamics:
where \(x_i^t\) is the state of node \(i\), \(w_{ij}^t\) is the weight between nodes \(i\) and \(j\), and \(N_i^t\) contains the neighbors of node \(i\); the superscript \(t\) indicates quantities at time \(t\). The weights \(w_{ij}^t\) are known and the scaling factor \(\alpha\) is unknown.
One can also write the dynamics at the graph level,
where \(W^t\) is the (weighted) adjacency matrix of the graph. If one knows \(W^t\), then it is natural thought to try to incorporate this information in the model and its training.
In fact, in this case, knowing \(W^t\), one could just fit \(\alpha\) by linear regression.
If one is to use a generic NN to fit the model, it would be
But -
Usually \(W^t\) is large, and directly inputing \(W^t\) to NN would dramatically increase the model size and be memory consuming.
\(W^t\) is typically sparse, and one could store it in a compact sparse format (e.g., COO or CSR), whose size depends on the number of edges \(|E|\). However, with chaning topology, \(|E|\) would change, and this creates nuance in defining a vanilla NN model.
Problem Setup¶
The data generation is done in a separate script in the repo: scripts/ltg_dt_tv/gen_data.py. Stage the generated topology_*.npz and data_*.pkl files under examples/linear_graph/data/.
import pickle
from pathlib import Path
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import numpy as np
import torch
from dymad.io import load_model
from dymad.models import DLDMG
from dymad.training import NODETrainer
from dymad.utils import plot_summary, plot_trajectory
EXAMPLE_DIR = Path.cwd()
DATA_DIR = EXAMPLE_DIR / 'data'
LTV_DATA_CONFIG = EXAMPLE_DIR / 'ltv_data.yaml'
def _load_case_data(path):
try:
data = np.load(path, allow_pickle=True)
return data.item() if isinstance(data, np.ndarray) and data.shape == () else data
except Exception:
with open(path, 'rb') as handle:
return pickle.load(handle)
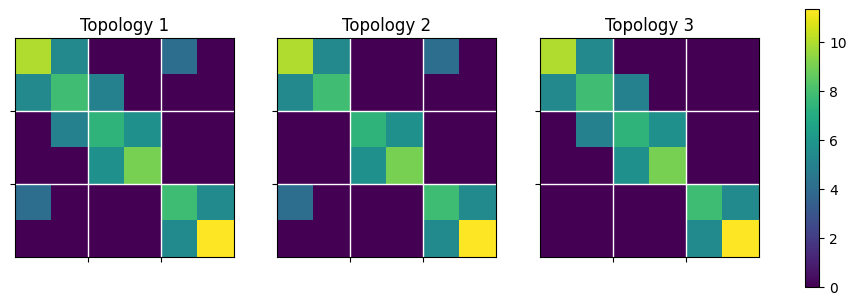
First is topology. Here we consider a 6-state system, and the adjacency matrices are plotted below. Every two states are strongly coupled (bright color), and among the two-state groups the interaction is weaker. Three topologies are considered: #2 and #3 each removes one edge from #1.
data = np.load(DATA_DIR / 'topology_n2_s3_k4_s10.npz')
AAs = data['AAs']
nSubSys = 3
nStates = 2
vmn1, vmx1 = np.min(AAs[0]), np.max(AAs[0])
tcks = np.arange(nStates, nSubSys * nStates, nStates) - 0.5
f, ax = plt.subplots(1, nSubSys, figsize=(4 * nSubSys, 4))
for n in range(nSubSys):
im0 = ax[n].imshow(AAs[n], vmin=vmn1, vmax=vmx1)
ax[n].set_title(f'Topology {n+1}')
ax[n].set_xticks(tcks)
ax[n].set_yticks(tcks)
ax[n].grid(which='both', color='white', linewidth=1.0)
ax[n].set_xticklabels([])
ax[n].set_yticklabels([])
cbar = f.colorbar(im0, ax=ax.tolist(), shrink=0.9, orientation='vertical');
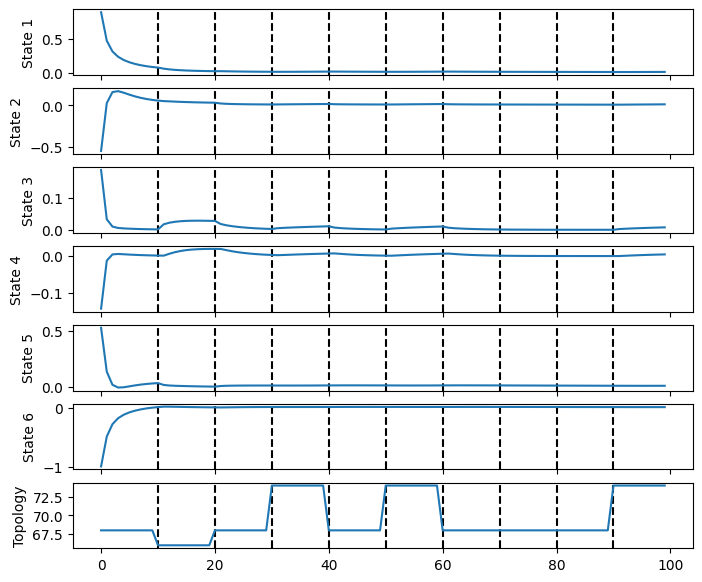
In training, the topology randomly switches every 10 steps, which changes the dynamics. As a result, the responses are non-smooth at topology switch. In the topology plot, we are showing the sum of edge indices to indicate different topologies.
In testing, the topology will randomly switch every 5 steps (shown later).
data_trn = DATA_DIR / 'data_n2_s3_k4_s10.pkl'
data_tst = DATA_DIR / 'data_n2_s3_k4_s20.pkl'
data = _load_case_data(data_trn)
tdx = 10
xs = np.asarray(data['x'][tdx])
ei = data['ei'][tdx]
Aidx = [np.sum(e) for e in ei]
Nt, Nx = xs.shape
T = np.arange(Nt)
f, ax = plt.subplots(Nx + 1, 1, sharex=True, figsize=(8, Nx + 1))
tdx = np.arange(1, 10) * 10
for n in range(Nx + 1):
for t in tdx:
ax[n].axvline(t, color='k', linestyle='--')
for n in range(Nx):
ax[n].plot(xs[:, n], label=f'SubSys {n+1}')
ax[n].set_ylabel(f'State {n+1}')
ax[-1].plot(T, Aidx)
ax[-1].set_ylabel('Topology');
Training and Results¶
Next we define the model and then train. The graph convolution layer is chosen to be GraphConv; it is one simple GCL that multiplies weights to the inputs.
The checkpoint directory follows model.name, so this notebook now matches the maintained script example and writes kura_model.pt plus the matching summary artifacts.
mdl_ld = {
'name': 'kura_model',
'encoder_layers': 0,
'decoder_layers': 0,
'processor_layers': 1,
'hidden_dimension': 2, # Per node
'gcl': 'gcnv', # GraphConv
'gcl_opts': {'bias': False},
'activation': 'none', # Linear problem, so no nonlinearity
'weight_init': 'xavier_uniform',
}
trn_nd = {
'n_epochs': 1000,
'save_interval': 50,
'load_checkpoint': False,
'learning_rate': 1e-2,
'decay_rate': 0.999,
'reconstruction_weight': 1.0,
'dynamics_weight': 1.0,
'sweep_lengths': [2, 4, 8],
'sweep_epoch_step': 100,
'chop_mode': 'unfold',
'chop_step': 0.5,
}
In the base YAML file, transform_ew controls the edge-weight transform and the dataset path is injected at runtime. In this simple problem, a vanilla Identity transform is used.
"""ltv_data.yaml
data:
n_samples: 200
n_steps: 100
double_precision: true
transform_ew:
type: "identity"
split:
train_frac: 0.75
dataloader:
batch_size: 64
"""
The following is the usual training procedure - nothing different from the non-graph model.
config_path = LTV_DATA_CONFIG
config_mod = {
'data': {'path': str(data_trn)},
'model': mdl_ld,
'training': trn_nd}
trainer = NODETrainer(config_path, DLDMG, config_mod=config_mod)
trainer.train();
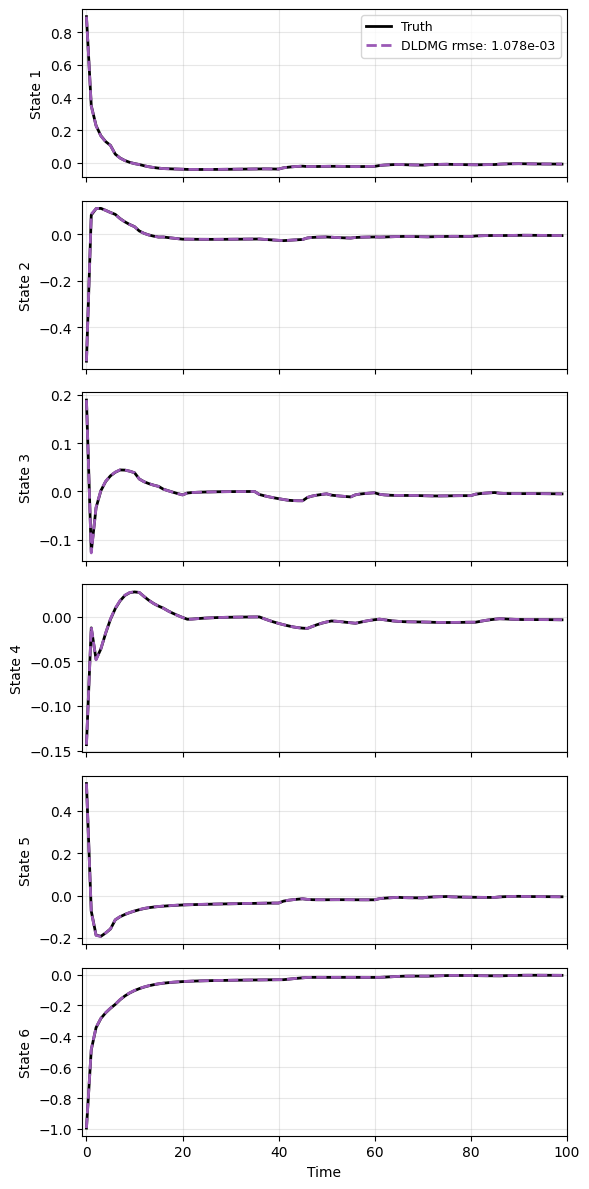
And lastly plotting the results - nearly perfect match, even with a different frequency of topology variation.
data = _load_case_data(data_tst)
tdx = 10
x_data = np.asarray(data['x'][tdx])
t_data = np.arange(0, x_data.shape[0])
ei_data = data['ei'][tdx]
ew_data = data['ew'][tdx]
res = [x_data]
with torch.no_grad():
_, prd_func = load_model(DLDMG, 'kura_model.pt')
pred = prd_func(x_data, t_data, ei=ei_data, ew=ew_data)
res.append(pred)
plot_trajectory(
np.array(res), t_data, 'LTGV',
labels=['Truth', 'DLDMG'], ifclose=False);
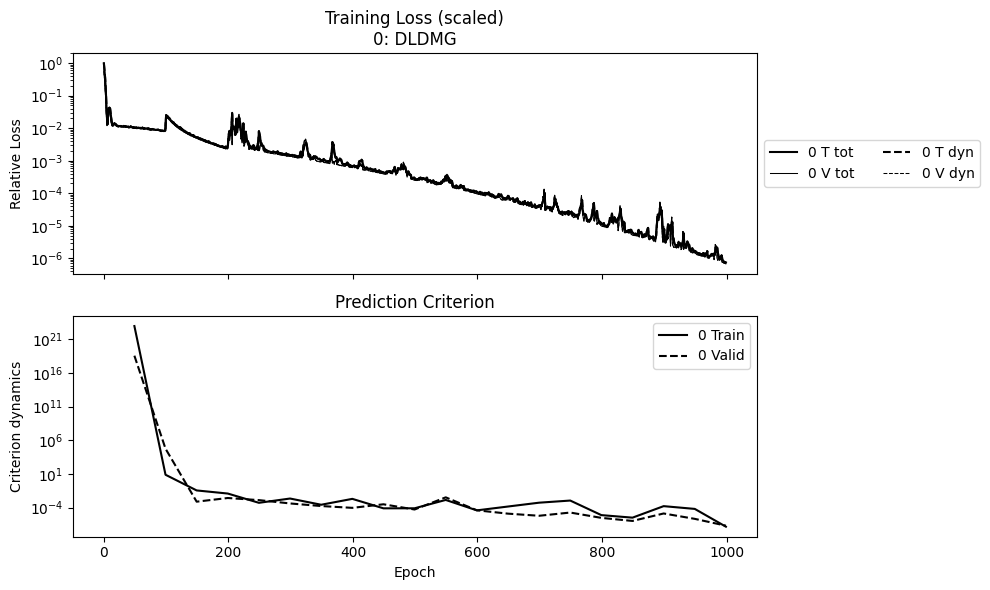
plot_summary(['kura_model'], labels=['DLDMG'], ifclose=False)
[NpzFile 'kura_model/kura_model_summary.npz' with keys: model_name, total_training_time, avg_epoch_time, final_train_loss, final_valid_loss...]